1. Introduction
In this article we will present an Application for interacting with an android wear smartwatch through wrist gestures. As smartwatches are typically worn in the wrist, one would expect a hands-free way of interaction, leaving the other hand free for other activities. Android wear also offers a voice activated interaction, however this wouldn’t be a solution in several social situations (i.e. during a business conference) or in situations in which users require their own privacy.
Such application could greatly improve the accessibility of smartwatches for one-handed users, who may be either amputees or users who are unable to use both hands, as in the case of cerebral palsy which usually is combined with a speech impairment as well, turning the smartwatch to a completely useless device.
The author of this article falls in this last case of users, so this article is motivated by the author’s self interest and is being publicized in hope that it will benefit other people as well.
1.1. Literature review
Literature in the field of hands-free interaction with a wrist wearable device, offer many examples, such as the Gesturewrist system which allow users to interact with wearable or nearby computers by using gesture-based commands [1]. Guo and Paek explored two tilt-based interaction techniques for menu selection and navigation: AnglePoint, which directly maps the position of a virtual pointer to the tilt angle of the smartwatch, and ObjectPoint, which objectifies the underlying virtual pointer as an object imbued with a physics model [2]. Xu et al. showed that motion energy measured at the smartwatch is sufficient to uniquely identify user’s hand and finger gestures [3]. Gong et al. proposed and studied a new input modality, WristWhirl, that uses the wrist as an always-available joystick to perform one-handed continuous input on smartwatches [4]. In Chen et al.’s Swipeboard, characters are entered with two swipes; the first swipe specifies the region where the character is located, and the second swipe specifies the character within that region [5]. Furthermore, they also created ZoomBoard which uses iterative zooming to enlarge otherwise impossibly tiny keys to comfortable size [6]. Finally, Wen et al. in Serendipity demonstrated the potential to distinguish 5 fine-motor gestures like pinching, tapping and rubbing fingers using integrated motion sensors (accelerometer and gyroscope) in off-the-shelf smartwatches [7].
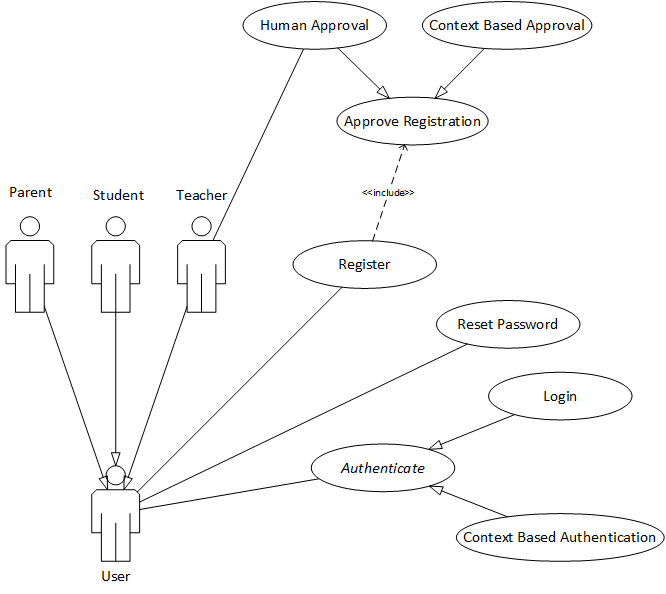
2. The HandsFree Wear application
HandsFree Wear is an Accessibility Service [8] for Android Wear Smartwatches [9] which gives you the ability to use discrete wrist gestures to select controls and interact with them without the need of a second hand or voice input. Android wear already provides a set of three distinct wrist gestures [10] that can be performed in a smartwatch. HandsFree Wear on the other hand can recognize 14 distinct wrist gestures and map these into touch gestures or AccessibilityActions [11] as follows:
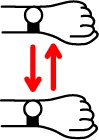
- Scroll Left: It is performed by moving your hand left and then back (Figure 1.a). It performs ACTION_SCROLL_LEFT or ACTION_DISMISS to the first visible element that supports either of these actions. If no such element exist it performs a horizontal swipe starting at 75% of screen’s width and ending at 25% of screen’s width.
- Scroll Right: It is performed by moving your hand right and then back (Figure 1.b). It performs ACTION_SCROLL_RIGHT or ACTION_DISMISS to the first visible element that supports either of these actions. If no such element exist it performs a horizontal swipe starting at 25% of screen’s width and ending at 75% of screen’s width.
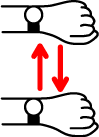
- Scroll Up: It is performed by moving your hand towards your body and then back (Figure 1.c). It performs ACTION_SCROLL_UP or ACTION_SCROLL_BACKWARD to the first visible element that supports either of these actions. If no such element exist it performs a vertical swipe starting at 25% of screen’s height and ending at 75% of screen’s height.
- Scroll Down: It is performed by moving your hand away from your body and then back (Figure 1.d). It performs ACTION_SCROLL_DOWN or ACTION_SCROLL_FORWARD to the first visible element that supports either of these actions. If no such element exist it performs a vertical swipe starting at 75% of screen’s height and ending at 25% of screen’s height.
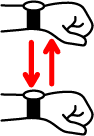
- Click: It is performed by moving your hand down and then back (Figure 1.e). It performs ACTION_CLICK, ACTION_COLLAPSE or ACTION_EXPAND to the selected element.
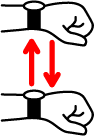
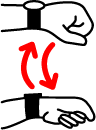
- Go Back: It is performed by moving your hand up and then back (Figure 1.f). It performs the Global Action Back (GLOBAL_ACTION_BACK).
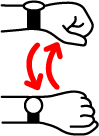
- Select Next: It is performed by flicking your wrist towards you and then back (Figure 1.g). It selects the next element (breadth first search) that supports any of the AccessibilityActions described here.
- Select Previous: It is performed by flicking your wrist towards you and then back (Figure 1.h). It selects the previous element (breadth first search) that supports any of the AccessibilityActions described here.
- Swipe Left: Two times in a row the Scroll Left gesture (1). It performs a horizontal swipe from right to left in the whole screen’s width.
- Swipe Right: Two times in a row the Scroll Right gesture (2). It performs a horizontal swipe from left to right in the whole screen’s width.
- Swipe Down: Two times in a row the Scroll Up gesture (3). It performs a vertical swipe from top to bottom in the whole screen’s height, essentially the same as scrolling a list up.
- Swipe Up: Two times in a row the Scroll Down gesture (4). It performs a vertical swipe from bottom to top in the whole screen’s height, essentially the same as scrolling a list down.
- Long Click: Two times in a row the Click gesture (5). It performs ACTION_LONG_CLICK, to the selected element.
- Google Assistant: Two times in a row the Go Back gesture (6). It performs the Global Action Power Dialog (GLOBAL_ACTION_POWER_DIALOG), which shows the Google Assistant.
 (c) |
 (d) |
 (e) |
 (f) |
 (g) |
 (h) |
(a) |
(b) |
Figure 1: Wrist gestures
2.1. Data
Our initial intuition suggested that data from the smartwatch’s accelerometer and/or gyroscope would be proved to provide sufficient data and after some preliminary tests, we concluded that Android’s linear acceleration sensor [12] was enough as we will show in the next sections.
In order to record data we created the required smartwatch and desktop application. Both applications are available in the project’s github repository [13]. The SensorData Accessibility Service runs in the smartwatch and constantly sent linear accelerometer’s data to an HTTP server which is provided by the DataProcess project [13].
Class gr.ictpro.jsalatas.gestures.ui.recorddata.RecordDataUI in that projects, starts an embedded HTTP Server which receives incoming data from the smartwatch, stores these in a SQLite Database and also visualizes it in the screen as a form of visible feedback to the user (Figure 2).
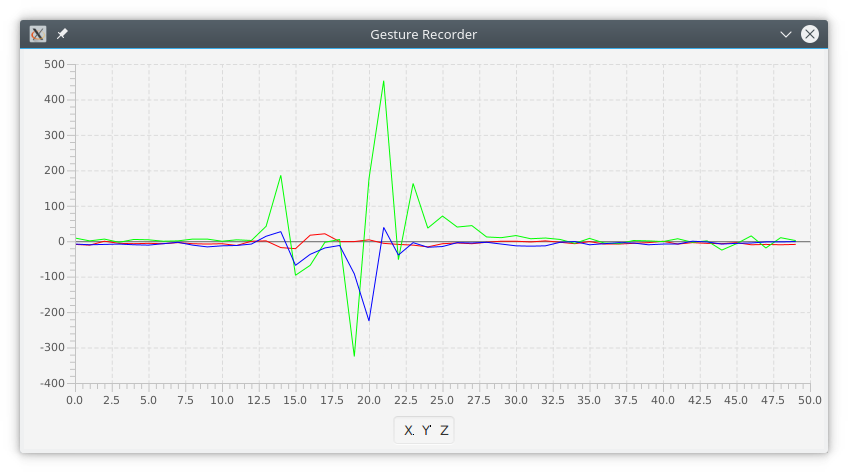
Figure 2: The Gesture Recorder UI
A total of 156.730 linear accelerometer’s readings where saved as the author of this article performed each of the gesture above several times, giving enough space between each gesture in order to be able to distinguish it.
2.2. Preprocess
Having the raw data, our first task was to go through the data and manually tag the segments that a gesture was performed. The DataProcess project [13] contains the class gr.ictpro.jsalatas.
gestures.ui.classify.ClassifyUI which brings up a GUI with tools necessary to pan, zoom in the chart and and tag segments of data with a particular gesture (Figure 3).

Figure 3: The Classification UI, showing the tagging of a series of Select Next gestures
The window size (
")
 _i , i=0,1,\dots,w_t-1 \rbrace")
Class gr.ictpro.jsalatas.gestures.export.Csv contains the necessary code to export a series of a tagged vectors  _i")

 _i")

 _{i+j},c)_i , i=0,1,\dots,w_t-1-w_c , j=0,1,\dots,w_c-1 \rbrace")
Where

2.3. Model training and optimization
Having these instances, we switch to the python project named train [13][13.a], which is based on tensorflow [14] and keras [15], in order to build a Sequential model that recognizes such gestures. In general, the project contains all the necessary code in order to load the previously generated CSV file, split it into training and validation set and run a genetic algorithm with the objective of finding the optimal neural network parameters (in particular number of layer/neurons, activation functions, training algorithm and number of epochs). We also keep track of the recognition’s accuracy (percent). As an additional note, the input dataset is highly imbalanced with a dominant “no gesture” (0) output and needs to be weighted which is accounted by the relevant class weights.
We executed the genetic algorithm for 20 generations, having a population of 25 individual networks, and for the parameters shown in Table 1:
Table 1: Genetic Algorithm’s parameters
| Epochs: | 3000 |
| Number of Layers: | 1 |
| Maximum Number of Neurons per Layer: | 3000 |
| Activation: | [‘relu’, ‘elu’, ‘tanh’, ‘sigmoid’] |
| Optimizer: | [‘rmsprop’, ‘adam’, ‘sgd’, ‘adagrad’, ‘adadelta’, ‘adamax’, ‘nadam’] |
The best network after 20 generations had the parameters and performance as shown in the following Tables:
Table 2: Best Model
| Epochs: | 632 |
| Number of Layers: | 1 |
| Number of Neurons: | 2558 |
| Activation: | ‘sigmoid’ |
| Optimizer: | ‘adadelta’ |
Table 3: Best Model’s Performance (Validation set)
| Accuracy: | 96.37% |
| Loss: | 0.1214 |
Table 4: Best Model’s Confusion matrix (Training and Validation sets)
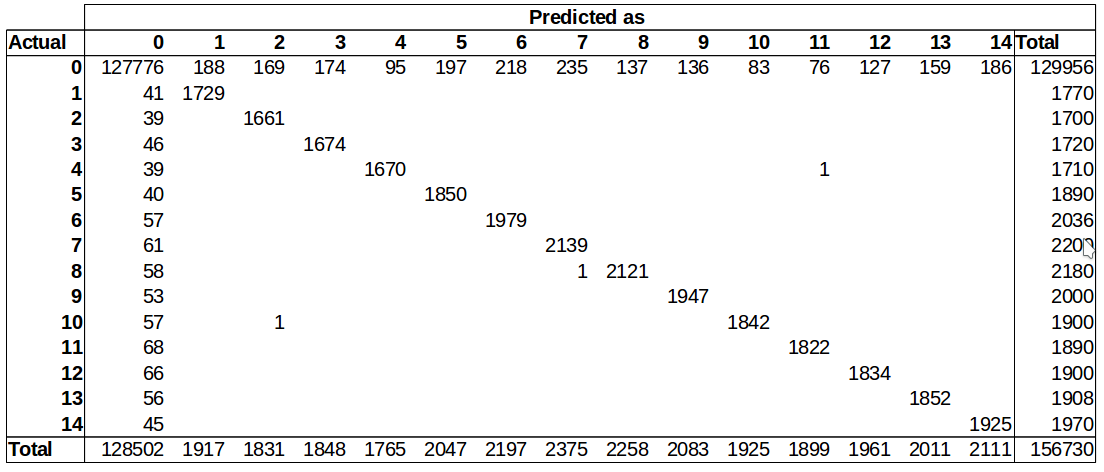
Having the model we converted it to a tensorflow graph and freeze it to a protobuf file then can be used in java code for the actual recognition.
2.4. Results
In project DataProject [13], class gr.ictpro.jsalatas.gestures.ui.predictions.
PredictionsUI contains the necessary code to use that protobuf model and visualize the predictions along with the actual class side by side with the

Figure 4: The Predictions UI.
As expected, a gesture is recognized after completed and it can can be recognized in a windows equal to 10 (
")

Figure 5: The Predictions UI, showing cases of false positives.
These type of false positives are easy to handle by taking into account the whole series of 10 (
2.5. Accessibility service in android
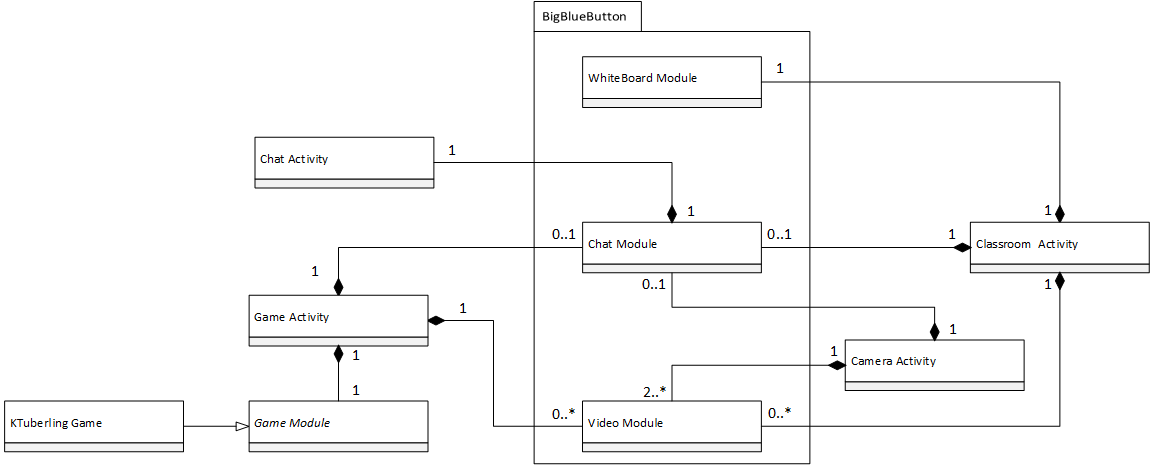
As mentioned, the HandsFree Wear application consists of an Accessibility service which recognizes the wrist gestures performed by the users and taking the relevant actions as depicted in Figure 6.

Figure 6: HandsFree Wear’s Activity Diagram
The HandsFree Wear application is available as beta version in Google’s play store [16].
2.5.1. Preliminary Evaluation
The application is currently used and evaluated by the author of this article in a daily basis, during the last 2-3 weeks in a Ticwatch E (Android 7.1.1 and Android Wear 2.8.0). The device’s hardware is more than efficient and it consumes about 1% of the battery’s capacity per hour (based on the author’s usage).
In general, with the exception of the issues described in the next section, the device was 100% accessible: Through the wrist gestures described previously, users can go through their notifications and dismiss them or open and interact with them, like reply to an email or instant message with an emoticon or a predefined phrase, start any application from the smartwatch’s launcher and interact with it, go through the device’s settings and modify these, etc.
2.5.2. Issues
At the moment maybe the most important issue is Google’s Input Methods for wearable devices (Figure 7), which is still an open research field as we saw in the Swipeboard [5] and Zoomboard [6] systems.


Figure 7: Google’s Input Methods (Android 7.1.1)
Another issue lies in the methodology we used to collect data. The trained model is unable to recognize any gesture while the user is walking. It can however recognize gestures (although at a lower, unknown accuracy) if the user is inside a car moving with a relative steady speed.
Moving to specific applications, it seems that the watch-face’s compilations (Figure 8), don’t seem to advertise the actions the support and most importantly ACTION_CLICK, and thus turning them non selectable through Select Next / Select Previous wrist gestures.

Figure 8: Watch-face with four compilations
Finally, the Google Maps application seem to have two issues. The buttons overlay in map canvas seem to hide after some time of inactivity, giving full visibility to the map (Figure 9) and eventually making them inaccessible in to HandsFree Wear service. Also the items in “Around Here” list (Figure 10) don’t seem to advertise the ACTION_CLICK method, and thus turning them non selectable through Select Next / Select Previous wrist gestures.
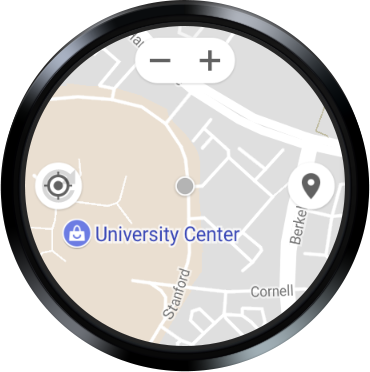

Figure 9: Google Maps with visible and hidden button overlay

Figure 10: Google Maps “Around Here” list
3. Future work – Conclusion
As a general conclusion of our study, it seem that the created HandsFree Wear application is usable for most common task on a daily basis, at least from the author’s perspective. It would be interesting to have feedback from other users as well and this is the primary reason that we are making it available either as a ready to use application through Google Play Store [16] or in the form of its source code [13]. It would be also interested evaluate the model’s performance in recognizing wrist gestures that are performed from other people. Our first impression here is that the model wouldn’t perform that well, but users should be able to learn how to perform the gestures in a way recognized by the model.
Regarding the input methods issue, we are planning to further investigate it, and preferably create an accessible (in the HandsFree Wear application’s context) input method with an initial idea to create and evaluate a phonepad like UI with T9 capabilities.
Finally, regarding the issues in Google Maps application, after further investigating it, we plan to compile a bug report and communicate with google.
As a final remark, it is the author’s impression that in the IoT era we may need to redefine what accessibility means, giving the fact that apparently most the current research is focused towards voice-user interfaces, which are not suitable for all users. We believe that we need to make sure that either speech recognition works for all users and in a language that they understand, or offer alternative input methods, that may even not require voice or limp use at all like [17].
References
[1] Rekimoto, J., 2001. Gesturewrist and gesturepad: Unobtrusive wearable interaction devices. In Wearable Computers, 2001. Proceedings. Fifth International Symposium on (pp. 21-27). IEEE.
[2] Guo, A. and Paek, T., 2016, September. Exploring tilt for no-touch, wrist-only interactions on smartwatches. In Proceedings of the 18th International Conference on Human-Computer Interaction with Mobile Devices and Services (pp. 17-28). ACM.
[3] Xu, C., Pathak, P. H., & Mohapatra, P. (2015, February). Finger-writing with smartwatch: A case for finger and hand gesture recognition using smartwatch. In Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications (pp. 9-14). ACM.
[4] Gong, J., Yang, X.D. and Irani, P., 2016, October. WristWhirl: One-handed Continuous Smartwatch Input using Wrist Gestures. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology (pp. 861-872). ACM.
[5] Chen, X.A., Grossman, T. and Fitzmaurice, G., 2014, October. Swipeboard: a text entry technique for ultra-small interfaces that supports novice to expert transitions. In Proceedings of the 27th annual ACM symposium on User interface software and technology (pp. 615-620). ACM.
[6] Oney, S., Harrison, C., Ogan, A. and Wiese, J., 2013, April. ZoomBoard: a diminutive qwerty soft keyboard using iterative zooming for ultra-small devices. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 2799-2802). ACM.
[7] Wen, H., Ramos Rojas, J. and Dey, A.K., 2016, May. Serendipity: Finger gesture recognition using an off-the-shelf smartwatch. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (pp. 3847-3851). ACM.
[8] AccessibilityService, Android Developers https://developer.android.com/reference/android/accessibilityservice/AccessibilityService.html, last accessed: 02/02/2018
[9] Android wear, https://www.android.com/wear/, last accessed: 02/02/2018
[10] Navigate your watch with wrist gestures, Android Wear Help, https://support.google.com/androidwear/answer/6312406?hl=en, last accessed: 02/02/2018
[11] AccessibilityNodeInfo.AccessibilityAction, Android Developers, https://developer.android.com/reference/android/view/accessibility/AccessibilityNodeInfo.AccessibilityAction.html, last accessed: 02/02/2018
[12] AccessibilityNodeInfo.AccessibilityAction, Android Developers, https://developer.android.com/reference/android/hardware/Sensor.html, last accessed: 02/02/2018
[13] HandsFree Wear Source Code, github, https://github.com/jsalatas/HandsFreeWear, last accessed: 02/02/2018
[13.a] Let’s evolve a neural network with a genetic algorithm, https://blog.coast.ai/lets-evolve-a-neural-network-with-a-genetic-algorithm-code-included-8809bece164, last accessed: 02/03/2018
[14] Tensorflow, https://www.tensorflow.org/, last accessed: 02/02/2018
[15] Keras Ducumenntation, https://keras.io, last accessed: 02/02/2018
[16] HandsFree Wear Application, Google Play Store, https://play.google.com/store/apps/details?id=gr.ictpro.jsalatas.handsfreewear, last accessed: 02/02/2018
[17] Assistive Context-Aware Toolkit (ACAT), https://github.com/intel/acat, last accessed: 02/02/2018